Web Scraping with Clojure - Scraping Hacker News
Enlive is a Clojure library that can be used for generating dynamic server-side content as well as scraping websites.
Scraping websites is sometimes required when they do not provide an API. Although Hacker News does have an API, will show how to scrape its website using Enlive's selectors.
Create a Clojure project
We are using Clojure CLI and clj-new to create a new project
clojure -A:new app practicalli/webscraper
Add the Enlive library as a dependency to the deps.edn file in the newly created project, along with clojure which should already be there as a dependency.
:deps
{org.clojure/clojure {:mvn/version "1.10.1"}
enlive {:mvn/version "1.1.6"}}
Now we are read to start the REPL, either via your editor, using clj or using rebel readline clojure -A:rebel if installed.
See details of how to install these
Open the src/practicalli/webscraper-enlive.clj file and add code for our scraper
Adding a website to scrape
A def function could be used to bind the URL to a name
(def hacker-news-url "https://news.ycombinator.com/")
Enlive will scrape a website using the html-resource function, which takes an HTML object (java.net.URL) and converts it into a nested Clojure data structure, a bit like a simplfied Document Object Model (DOM).
(html/html-resource (java.net.URL. hacker-news-url))
The html-resource function returns a sequence of hash-maps, containing Clojure keywords that represent the HTML tags and CSS styles.
Here is just a small part of this output, specifically around the <td class="title"> tag
{:tag :td,
:attrs {:class "title"},
:content
({:tag :a,
:attrs
{:href
"https://www.roadandtrack.com/new-cars/car-technology/a31451281/koenigsegg-gemera-engine-specs-analysis/",
:class "storylink"},
:content
("Koenigsegg’s 2.0-Liter No-Camshaft Engine Makes 600 Horsepower")}
{:tag :span,
:attrs {:class "sitebit comhead"},
:content
(" ("
{:tag :a,
:attrs {:href "from?site=roadandtrack.com"},
:content
({:tag :span,
:attrs {:class "sitestr"},
:content ("roadandtrack.com")})}
")")})}
Caching scraped websites
When we are developing a scraping app we could end up hitting a website hundreds (thousands) of times and if lots of people did that it would not be good for that website.
Using the caching nature of the def function, we can bind the result of calling the website to a name. Each subsequent time the name bound to the results is evaluated, the existing data is used and the website is not visited. This can also speed up your development if there is a slow connection to that website.
(def website-content-hacker-news
"Get website content from Hacker News
Returns: list of html content as hash-maps"
(html/html-resource (java.net.URL. hacker-news-url)))
Note: alternatively you could use a command line tool to pull down a website to a file, allowing you to work with the file outside the REPL.
Inspecting what to scrape
There is typically a lot of structure and styling around the content of a web page, so finding the right starting point is sometimes tricky. Using a browers Inspector tool can help find the right tags quickly.
With the website open in your browser, use the Inspect Element tool to look for unique HTML tags and CSS classes that surround the content you need.
Inspecting the headings in hacker news webpage, the text of each headline is inside a td tag, a table data cell. The headings td tag has as a CSS style called title, so it can be referenced as .td.title
Getting Selective with webpage content
Enlive uses selectors to extract specific content from the website content.
Selectors are define as a vector containing keywords that represent the HTML tags and CSS classes in the original web page.
To get all the matching headings we use a selector with the Enlive select function on the parsed
(html/select website-content-hacker-news [:td.title :a])
This returns a Clojure data structure containing any matching parts of the website.
To see the results clearly, we can either pretty print them or just take the first part of the data structure.
(take 1
(html/select website-content-hacker-news [:td.title :a]))
Example output:
;; => ({:tag :a,
;; :attrs {:href "https://www.roadandtrack.com/new-cars/car-technology/a31451281/koenigsegg-gemera-engine-specs-analysis/", :class "storylink"},
;; :content ("Koenigsegg’s 2.0-Liter No-Camshaft Engine Makes 600 Horsepower")})
The Enlive text function extracts the value from the :content key. Mapping the text function over our selected keys returns just the content we want
(map html/text
(html/select
website-content-hacker-news
[:td.title :a]))
This will return a list of all the matching headlines, each headline will be a string.
("Koenigsegg’s 2.0-Liter No-Camshaft Engine Makes 600 Horsepower" "roadandtrack.com" "Git Partial Clone lets you fetch only the large file you need" "gitlab.com" "Pence says European travel ban will extend to U.K. and Ireland" "axios.com" "Coronavirus has caused a bicycling boom in New York City" "grist.org" "Iceland radically cut teenage drug use" "weforum.org")
Enlive Selectors
Enlive selectors are data structures that identify one or more HTML nodes. They describe a pattern of data—if the pattern matches any nodes in the HTML data structure, the selector will select those nodes. A selector may select one, many, or zero nodes from a given HTML document, depending on how many matches the pattern has.
The full reference for valid selector forms is quite complex, and beyond the scope of this recipe. See the formal selector specification for complete documentation.
The following selector patterns should be sufficient to get you started:
[:div]
Selects all <div> element nodes.Selects all <div> element nodes with a CSS class of "sidebar".Selects the <div> element with an HTML ID of "summary".Selects all <span> elements that are descendants of <p> elements.Selects only <span> elements inside an <li> element inside a <ul> element inside a <div> element with a CSS style of "menu".Selects all <div> elements that are the second children of their parent elements. The double square brackets are not a typo—the inner vector is used to denote a logical and condition. In this case, the matched element must be a <div>, and the nth-child predicate must hold true.Other predicates besides nth-child are available, as well as the ability to define custom predicates. See the Enlive documentation for more details.
Finally, there is a special type of selector called a range selector that is not specified by a vector, but rather by a map literal (in curly braces). The range selector contains two other selectors and inclusively matches all the nodes between the two matched nodes, in document order. The starting node is in key position in the map literal and the ending node is in value position, so the selector {[:#foo] [:#bar]} will match all nodes between nodes with a CSS ID of "foo" and a CSS ID of "bar".
The example in the solution uses a range selector in the defsnippet form to select all the nodes that are part of the same logical blog post, even though they aren’t wrapped in a common parent element.
Getting the voting points
Each heading can be voted for, which I believe keeps it on the site longer. The points and when the article was posted can be pulled out using different selectors.
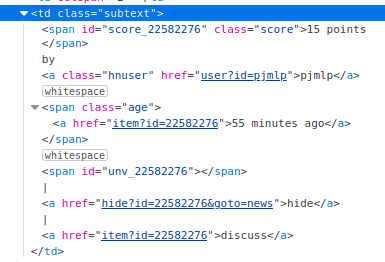
The .td.subtext has several span tags as children and each span tag has a CSS selector, however, those CSS selectors are dynamically generated and therefore random.
So the Enlive first-child function is used to get the span content.
Then the Enlive text function pulls out all the values from the :content keys in the selected content.
(map html/text
(html/select
website-content-hacker-news
[:td.subtext html/first-child]))
Make functions to get headings and points
The headings function
(defn headlines
"Headlines of the currently published stories
Arguments: web address as a string
Returns: list of headlines as strings"
[website-url]
(map html/text
(html/select
#_(website-content website-url)
;; DEV: cached website
website-content-hacker-news
[:td.title :a])))
The points function
(defn article-scoring
"Points of the currently published stories
Arguments: web address as a string
Returns: headlines in hiccup format "
[website-url]
(map html/text
(html/select
;; (website-content website-url)
;; DEV: cached website
website-content-hacker-news
[:td.subtext html/first-child])))
Combining the results
A function to combine the results of heading and points
(defn headlines-and-scoring
"Putting it all together..."
[website-url]
(doseq [line (map #(str %1 " (" %2 ")")
(headlines website-url)
(article-scoring website-url))]
(println line)))
This function uses doseq to iterate over each line and print the results to the REPL (or standard out if run as a command line program). doseq itself returns nil.
For each line that is printed, we map an anonymous function over the two collections, one collection from each of our functions headlines and article-scoring
The anonymous function gets a value from each of the collections and combines them in a string, putting the value from the second collection, article-scoring in round brackets.
#(str %1 " (" %2 ")")
Combining selectors
The selectors passed to Enlive's select function can be combined in a Clojure set.
So to get both headings and scoring we can use the following set as an arguments
#{[:td.title :a] [:td.subtext html/first-child]}
Then we can combine the prevous headings and article-scoring functions into a single function.
(defn headlines-and-scoring []
(map html/text
(html/select website-content-hacker-news
#{[:td.title :a] [:td.subtext html/first-child]})))
The results of this function have the headings and scoring interleaved. Using the Clojure partition function pairs each heading and score
The anonymous function is updated to destructure the arguments, so we get a separate heading and score, which is then assembled in the same string form.
(defn print-headlines-and-scoring []
(doseq [line (map (fn [[h s]] (str h " (" s ")"))
(partition 2 (headlines-and-scoring)))]
(println line)))
Summary
This just touches on the basics of Enilve and more examples will come in future articles.